Everyone building with voice AI right now is focused on the same things: which LLM is fastest, which TTS sounds most human, and how to squeeze latency under 500ms.
All valid questions. But there’s a layer underneath all of that which barely gets discussed, and it’s where production systems actually break.
The network layer.
I’ve been building real-time voice pipelines using Deepgram’s Voice Agent API and ElevenLabs for clients, and the hardest problems had nothing to do with the model.
There were protocol problems. Session problems. Codec problems.
The kind of problems that don’t show up in demos because demos run on a stable WiFi connection with one concurrent user.
Luke Curley, a former WebRTC engineer at Twitch and Discord who has spent years implementing these protocols at scale, just published “OpenAI’s WebRTC Problem”.
It put precise language to things I’d been feeling while building. This post is my ground-level view of the same problems.
The Real Problem: State
Before getting into protocols, it’s worth being precise about what actually breaks in a voice AI system when the network misbehaves.
It’s not audio quality. It’s not latency. It’s state.
Imagine a user mid-conversation:
“Large taro milk tea, oat milk, 75% sugar, and add a matcha latte.”
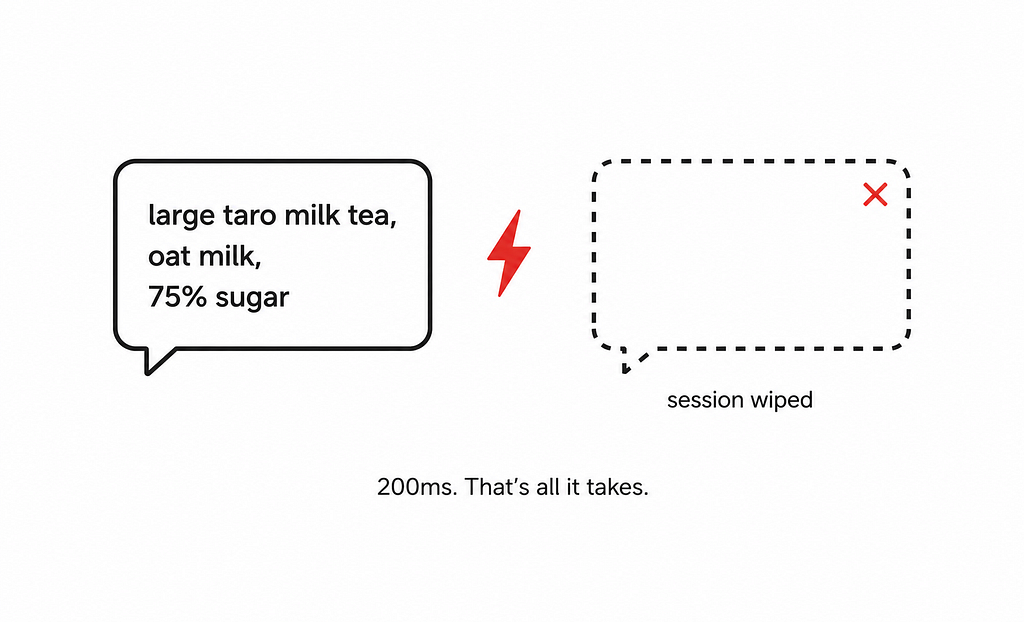
At this point, the system has accumulated meaningful context: two items, specific modifiers, and an in-progress order.
Where does that context live?
In memory, on a server, bound to a specific TCP connection identified by a socket file descriptor.
It is not in the model. It is not in a database.
It exists in your application’s heap, and its lifetime is tied directly to the connection.
Now the network blips for 200ms.
On a naively built system, that blip doesn’t just cause a stutter.
- The TCP connection times out.
- The client reconnects.
- Your server allocates a new socket.
- The new connection has no relationship to the old one; there’s no protocol-level mechanism to say “this is the same session.”
- Your session lookup returns nothing. You instantiate a fresh AI context.
The taro milk tea is gone.
The user has to start over. They won’t. They’ll hang up.
This is the fundamental challenge of stateful voice AI, and every other architectural decision, transport protocol, connection management, horizontal scaling strategy, is downstream of it.
Understanding why state is hard requires understanding what the transport layer does and doesn’t give you.
Why WebRTC Is the Wrong Tool Here
The intuitive choice for real-time audio is WebRTC.
It’s what browsers support natively.
It’s what conferencing apps use. OpenAI, Deepgram, and others expose WebRTC endpoints.
The mental model is: voice = WebRTC.
But WebRTC was designed for a specific problem that is almost the opposite of voice AI.

WebRTC’s core assumption
WebRTC is optimised for human-to-human conferencing, where the goal is to keep latency below the conversational threshold (~200ms round-trip) even at the cost of audio completeness.
The protocol achieves this through several aggressive mechanisms:
Packet dropping by design
WebRTC uses RTP (Real-time Transport Protocol) over UDP. UDP has no delivery guarantee and no retransmission.
When packets are lost, WebRTC’s jitter buffer makes a decision: wait for retransmission (which would add latency) or move on (which drops the data).
It moves on. This is correct behaviour for a conference call; a 20ms gap in human speech is imperceptible.
You can’t retransmit a WebRTC audio packet from within the browser; the implementation is hardcoded for real-time delivery or nothing.
Artificial latency to mask the problem.
Here’s the irony: WebRTC actually adds latency to compensate for its own packet dropping.
The jitter buffer is dynamically sized between 20ms and 200ms to smooth out network irregularities.
OpenAI’s blog post (which Curley references) reveals they add a step sleep before sending each audio packet to ensure it arrives exactly when it should be rendered.
They're introducing artificial delay to maintain the illusion of smooth playback, and then aggressively dropping packets to "keep latency low."
The two behaviours actively undermine each other.
No buffering of TTS output
When Deepgram or ElevenLabs generates TTS, they produce audio faster than real-time, say, 2 seconds of GPU time generating 8 seconds of audio.
A sensible system would buffer that audio locally and stream it to the client, so a brief network blip doesn’t cause a gap in playback.
WebRTC doesn’t buffer. It renders based on the arrival time.
A blip in the network means a gap in the voice. There’s no recovery.
The AI-specific failure mode
For human conversation, dropped packets are recoverable.
Brains are extraordinarily good at reconstructing partial audio; we do it constantly in noisy environments.
STT models are not.
When a dropped WebRTC packet clips the word “taro” out of “large taro milk tea,” the STT model doesn’t infer the missing word.
It transcribes “large milk tea.” The LLM reasons over that transcript.
It confidently adds the wrong item to the cart. The downstream tool call fires with incorrect parameters.
Everything breaks, and it breaks silently, with no error, because every component in the pipeline did its job correctly, given the input it received.
Curley frames this precisely: you would rather wait an extra 200ms for an accurate prompt than get a fast response to a garbage one.
WebRTC gives you no choice. It will degrade your prompt to maintain latency targets, regardless of what you’d prefer.
The infrastructure problems on top
Beyond the AI-specific failure, WebRTC creates serious operational headaches at anything beyond a trivial scale:
Port explosion
The WebRTC spec requires allocating a dedicated ephemeral port per connection for proper session identification.
Servers have ~65,000 ports total. At scale, this runs out quickly, and firewalls, especially corporate networks, block unfamiliar ephemeral ports aggressively.
Twitch and Discord both ended up muxing connections onto a single port, which is explicitly against the spec and breaks the source IP/port identification that WebRTC’s session management depends on.
Eight round-trips to establish a connection
A WebRTC session requires: TCP handshake, TLS 1.3, HTTP (for the signalling server), ICE, DTLS 1.2 (two round-trips), and SCTP.
That’s a minimum of 8 RTTs before a single audio frame is exchanged. For a voice AI that should feel instant, this is a significant UX tax.
Kubernetes incompatibility
Standard Kubernetes ingress controllers work on TCP/HTTP.
WebRTC’s media plane runs on UDP with port-per-connection requirements.
Getting WebRTC working cleanly behind a Kubernetes load balancer requires custom UDP routing, which most teams end up hacking rather than solving properly.
The WebSocket Bridge: Boring, Correct, Scalable
My approach(and what engineers who’ve spent years in this space consistently end up doing) was a plain WebSocket bridge.
TCP. No clever protocol. No custom load balancer.
Here’s why TCP is the right tradeoff for this use case:
TCP guarantees delivery and ordering.
If a packet is lost, TCP retransmits it before delivering subsequent data to the application.
The stream may slow down under congestion, but it never lies to you; it never delivers partial data and calls it complete.
For a voice AI where prompt accuracy directly determines response quality, this guarantee is worth the occasional latency spike.
You’d rather the user wait an extra 300ms than get a confident wrong answer.
WebSockets run on top of TCP.
They give you a persistent, full-duplex connection over a standard HTTP upgrade, which means they work with every existing piece of infrastructure:
- Kubernetes
- Ingress
- Standard load balancers
- Nginx
- CloudFlare
- AWS ALB
No custom UDP routing. No port management.
Standard monitoring.
When something breaks, your existing observability stack can see it.
The tradeoff is real: under heavy congestion, TCP’s retransmit behaviour can cause latency spikes that WebRTC’s packet-dropping avoids.
For voice AI as it exists today, where LLM inference latency already dominates the response time, this is an acceptable tradeoff.
The extra 50–100ms from a TCP retransmit is invisible next to a 1–2 second LLM round-trip.
The Codec Conversion Nobody Talks About
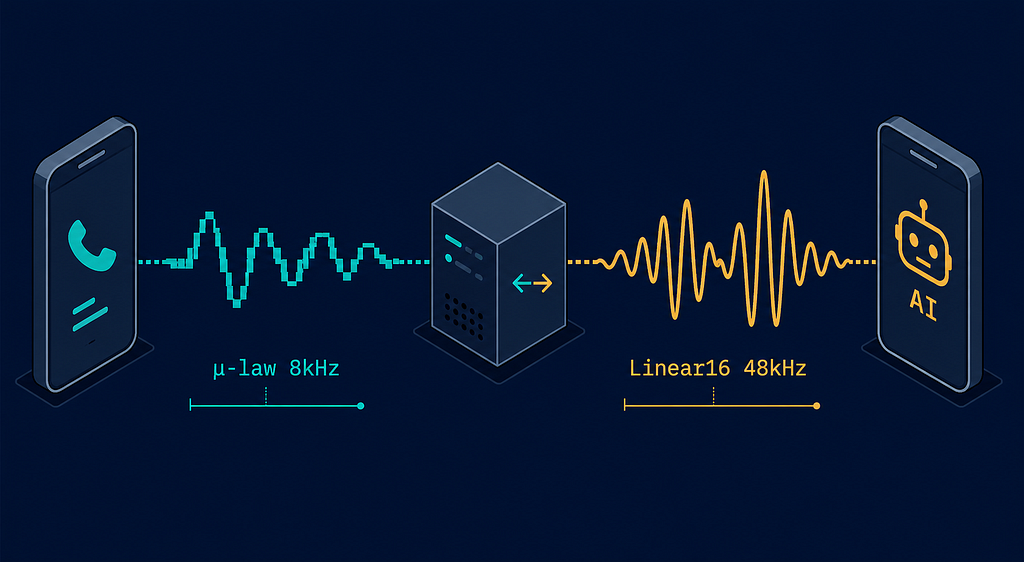
This is the part that gets glossed over in every architecture diagram, and it’s doing more work than it looks like.
Twilio’s Media Streams deliver audio encoded as G.711 µ-law (mu-law) at 8kHz, 8-bit.
This is not an arbitrary choice; it’s the standard encoding for PSTN (Public Switched Telephone Network) infrastructure, optimised for voice intelligibility over narrow-bandwidth copper lines.
The µ-law companding algorithm applies a logarithmic compression curve that allocates more quantisation levels to quiet sounds (where human speech perception is most sensitive) and fewer to loud sounds.
The result is good voice quality in 8-bit at the cost of audio fidelity outside the speech frequency range.
Voice API wants Linear16 PCM at 48kHz, 16-bit.
Linear16 is raw, uncompressed audio: each sample is a 16-bit signed integer representing the raw amplitude at that moment.
At 48kHz, that’s 48,000 samples per second. No companding. No compression. Just the waveform.
The conversion between these two formats involves several steps, happening in real time on every frame of every concurrent call:
1. µ-law decoding
Each 8-bit µ-law sample is decoded to a 16-bit linear PCM value using a lookup table or the standard decoding formula.
This expands the 256 quantisation levels of µ-law back into the full 16-bit range (−32768 to 32767).
2. Sample rate conversion (upsampling 8kHz → 48kHz)
This is the computationally non-trivial step. You can’t just insert zeros between samples (zero-order hold would introduce aliasing).
Proper upsampling requires interpolation, typically linear or sinc interpolation, to reconstruct the waveform at the higher sample rate.
At a 6x ratio (8kHz to 48kHz), you’re generating 6 output samples for every input sample.
The quality of this step directly affects STT accuracy: poor interpolation introduces spectral artefacts that degrade transcription, particularly for fricatives and sibilants (s, f, sh sounds) that already sit near the Nyquist limit of 8kHz audio.
3. Reverse conversion for TTS output
Everything above runs in reverse for audio coming back from Deepgram’s TTS. Linear16 at 48kHz must be downsampled to 8kHz and re-encoded to µ-law before Twilio will play it.
Downsampling requires low-pass filtering before decimation to avoid aliasing, a step that’s easy to skip and produces noticeably worse audio if you do.
The bridge runs this pipeline bidirectionally, on every 20ms audio frame (Twilio’s default chunk size), for every concurrent call.
It’s not glamorous work.
It’s the toll booth every byte passes through, and if it’s slow or introduces artefacts, every downstream component, STT accuracy, LLM reasoning, and user experience, degrades with it.
When working with ElevenLabs for TTS on client projects, the same fundamental mismatch exists on the return path.
The telephony layer and the AI layer speak different audio dialects, and something has to translate between them. There’s no shortcut.
The Scaling Problem: Sticky Sessions
The WebSocket bridge works correctly on a single server.
It starts to break the moment you introduce horizontal scaling, and the failure mode is worth understanding precisely.
Each call’s session state lives in memory, on a specific server instance. When Twilio connects a WebSocket, it connects to a specific IP address.
Every subsequent audio frame from that call arrives on the same TCP connection, to the same process, where the session object lives.
Now add a load balancer.
A standard round-robin load balancer routes each new connection to whatever backend has capacity.
If a call’s initial WebSocket connection lands on Server A, and Server A restarts mid-call, the reconnection might land on Server B.
Server B has no record of the session.
The call_sid lookup returns null. The context is gone. The standard mitigations:
Sticky sessions (IP affinity)
Configure the load balancer to route all traffic from a given source IP to the same backend.
This works until the client’s IP changes (WiFi to 5G, NAT rebinding) or the backend restarts.
Fragile at scale but functional for low-concurrency deployments.
External session store
Move session state out of process memory into Redis or a similar low-latency store.
The session is keyed bycall_sid, which Twilio includes in every WebSocket connection.
Any backend can reconstruct the session from Redis on reconnect.
This is the correct production solution, and it's what OpenAI's blog post describes them doing at scale for WebRTC session routing, using Redis to map source IP/port to backend server.
The Redis approach has its own costs: every session read and write now incurs a network round-trip to the store.
For a voice pipeline processing 20ms audio frames, that’s potentially 50 reads per second per call hitting Redis.
At meaningful concurrency, this becomes a bottleneck and a single point of failure. You trade in-process simplicity for distributed complexity.
Why QUIC Solves This Elegantly

This is where Luke Curley’s article gets genuinely exciting, and worth understanding in detail rather than dismissing as future speculation.
The root cause of the sticky session problem is that TCP (and therefore WebSocket) connections are identified by a 4-tuple: (source IP, source port, destination IP, destination port).
If any element of that tuple changes, the client switches from WiFi to 5G, NAT rebinds the source port, the load balancer IP changes, and the connection is severed.
There's no protocol-level continuity.
The client must reconnect from scratch.
QUIC uses Connection IDs instead.
Every QUIC packet carries a Connection ID chosen by the receiver (the server) at handshake time.
The Connection ID is opaque to the network, routers, and NATs can’t interpret it, only the endpoint that issued it.
When the client’s IP changes, QUIC’s connection migration mechanism sends a PATH_CHALLENGE on the new path.
Once the server validates the new path, all subsequent packets use the new source address while maintaining the same Connection ID.
From the application layer’s perspective, the connection never dropped. For our voice AI scenario, the customer’s phone switches from home WiFi to 5G while mid-order.
Under TCP/WebSocket, the connection dies, the session is potentially lost, reconnect is required.
Under QUIC, the connection migrates transparently in the background. The taro milk tea stays in the cart. The customer never notices.
QUIC-LB: stateless load balancing
The Connection ID approach enables something even more powerful for infrastructure: stateless load balancing.
The QUIC-LB IETF draft specifies a scheme where backend servers encode their own identifier into the Connection ID they issue at handshake time.
The flow works like this:
- Client initiates a QUIC connection to the load balancer’s anycast address
- The load balancer forwards the initial packet to a healthy backend
- Backend completes the handshake and generates a Connection ID that encodes its own backend ID in the first N bytes
- All subsequent packets from the client carry this Connection ID
- The load balancer decodes the backend ID from the first few bytes and forwards accordingly, no routing table, no Redis, no shared state
The load balancer becomes a pure forwarder. It doesn’t need encryption keys, doesn’t need session tables, and doesn’t need to coordinate with other load balancers.
The backend identity is carried in every packet. If a load balancer instance restarts, no state is lost because there was no state.
AWS Network Load Balancer added QUIC passthrough support in late 2025. The ecosystem is starting to catch up.
Why this isn’t production-ready for telephony today
The honest answer: Twilio doesn’t expose QUIC endpoints.
The PSTN → WebSocket bridge that telephony requires still runs over TCP.
QUIC’s benefits apply to the client-server leg of the connection, and if the client is a PSTN phone call mediated by Twilio, that leg is outside your control.
Where QUIC becomes immediately relevant is for web-based or app-based voice AI, browser clients using WebTransport (the QUIC-based WebSocket replacement), or native mobile apps using QUIC directly. For those use cases, the architectural benefits are available today.
For telephony pipelines specifically, the right move is to design your session state layer so that migrating to QUIC when Twilio or your telephony provider supports it is a transport swap, not an application rewrite.
The Tradeoffs, Honestly
No architecture is free. Here’s the real picture:
WebSocket / TCP:
- Guaranteed delivery → better STT accuracy
- Standard infrastructure → operational simplicity
- Session state in memory → sticky session problem at scale
- TCP retransmit under congestion → occasional latency spikes
- No native connection migration → client IP change = reconnect
WebRTC:
- Packet dropping → degraded STT accuracy
- Low jitter under good conditions → better perceived latency on stable networks
- Native browser support → simpler client-side integration
- Port-per-connection → infrastructure complexity at scale
- 8 RTT handshake → slower connection establishment
QUIC (future):
- Connection migration → session survives network changes
- Stateless load balancing → no shared routing state
- 1 RTT handshake → fastest connection establishment
- Multiplexed streams → audio + control on one connection without head-of-line blocking
- Ecosystem immaturity → not production-ready for telephony today
For voice AI as the technology currently stands, where LLM inference latency (500ms–2s) dominates the response time, and where STT accuracy directly determines output quality, WebSockets are the right default.
The TCP reliability guarantee is worth more than WebRTC’s jitter optimisation, and the operational simplicity is worth more than WebRTC’s theoretical latency advantages on stable networks.
What I’d Tell Anyone Building This
Design your session state layer as if it will eventually be external, even if you ship with in-process state first.
Use call_sid or equivalent as your session key everywhere.
Make the Redis migration a one-line config change, not an architectural rewrite.
Take the codec conversion seriously.
The µ-law → Linear16 path is where audio quality lives. Bad interpolation during upsampling will degrade your STT accuracy in ways that are difficult to debug because the transcripts will look almost right.
Test with real telephone audio, not clean microphone recordings.
Read the QUIC-LB draft.
Not because you’ll implement it tomorrow, but because understanding how Connection IDs enable stateless routing will change how you think about session management in every stateful system, not just voice AI.
The boring stuff, protocol choice, codec pipelines, and session management, is where production voice AI actually lives. The model is the easy part.
— Dilpreet Grover · dilpreetgrover.me
Voice AI Has a Networking Problem Nobody Talks About was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.