part 4
Last Updated: February 2026 Author: System Design Study Notes Goal: Understand Databases, Sharding, and Orchestrators easily using analogies, flowcharts (Mermaid), and real-world scenarios.
🗺️ 1. The Big Picture: SQL vs NoSQL

Choosing the right database is one of the most critical decisions in system design. It affects scalability, performance, consistency, developer productivity, and long-term maintainability.
This guide breaks down SQL (Relational) and NoSQL (Non-Relational) databases in depth, giving you the knowledge needed for both real-world architecture and system design interviews.
📋 Table of Contents
- What is SQL?
- What is NoSQL?
- Core Differences at a Glance
- Deep Dive: Data Model
- Deep Dive: Schema Design
- Deep Dive: Scalability
- Deep Dive: ACID vs BASE
- Deep Dive: CAP Theorem
- Types of NoSQL Databases
- NoSQL Indexing & Query Mechanisms
- Column Family DB — Deep Dive
- Query Language & Flexibility
- Performance Considerations
- SQL Database Limitations
- Sharding Key Selection Strategies
- Distributed Transactions & Cross-Shard Operations
- When to Use SQL
- When to Use NoSQL
- Real-World System Design Examples
- Group Chat Systems Architecture
- Caching Strategies
- Notification System Scaling
- Hybrid Approaches (Polyglot Persistence)
- Migration Strategies
- Decision Framework Flowchart
- Common Interview Questions
- Summary & Cheat Sheet
- Orchestrators & Managing Hardware
- Consistent Hashing & Load Distribution
- Hot Shard Detection & Capacity Planning
- Multi-Master Replication & Tunable Consistency
- Write-Ahead Logs (WAL)
- Data Migration Process (Two-Phase)
- Architecture Evolution Principles
What is SQL?
SQL (Structured Query Language) databases are relational databases that store data in predefined tables with rows and columns. They enforce a strict schema and use SQL as the query language.
Key Characteristics
https://medium.com/media/6b951b008ddce6fe1e56a28e3210b0e3/hrefPopular SQL Databases
https://medium.com/media/f0b55261535ce179810c4580754c0a5d/hrefExample: SQL Table Structure
-- Users Table
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Orders Table (relationship via foreign key)
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
user_id INTEGER REFERENCES users(id) ON DELETE CASCADE,
product VARCHAR(100) NOT NULL,
amount DECIMAL(10,2) NOT NULL,
status VARCHAR(20) DEFAULT 'pending',
ordered_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Query with JOIN
SELECT u.username, o.product, o.amount
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.status = 'completed'
ORDER BY o.ordered_at DESC;
What is NoSQL?
NoSQL (Not Only SQL) databases are non-relational databases designed for flexible schemas, horizontal scalability, and specific data model optimizations. They do not require a fixed table structure.
Key Characteristics
https://medium.com/media/40413c9cf9a68030d3722798c8f5a191/hrefPopular NoSQL Databases
https://medium.com/media/ba3143c8e2a97bd10b749dca6e3dfb57/hrefExample: NoSQL Document (MongoDB)
// Single document in "users" collection
{
"_id": "ObjectId('64a1b2c3d4e5f6g7h8i9j0k1')",
"username": "john_doe",
"email": "[email protected]",
"created_at": "2024-01-15T10:30:00Z",
"profile": {
"first_name": "John",
"last_name": "Doe",
"age": 30,
"interests": ["coding", "hiking", "photography"]
},
"orders": [
{
"order_id": "ORD-001",
"product": "Laptop",
"amount": 999.99,
"status": "completed",
"ordered_at": "2024-02-10T14:20:00Z"
},
{
"order_id": "ORD-002",
"product": "Mouse",
"amount": 29.99,
"status": "shipped",
"ordered_at": "2024-03-05T09:15:00Z"
}
]
}ja
// MongoDB Query
db.users.find(
{ "orders.status": "completed" },
{ username: 1, "orders.$": 1 }
).sort({ "orders.ordered_at": -1 });
Core Differences at a Glance
https://medium.com/media/2417e08b59afb617dd9de8e1c288109d/hrefDeep Dive: Data Model
SQL: Normalized Relational Model
Data is broken into separate related tables to minimize redundancy.
┌──────────────┐ ┌──────────────────┐ ┌──────────────┐
│ USERS │ │ ORDERS │ │ PRODUCTS │
├──────────────┤ ├──────────────────┤ ├──────────────┤
│ id (PK) │◄────│ user_id (FK) │ │ id (PK) │
│ username │ │ id (PK) │ │ name │
│ email │ │ product_id (FK) │────►│ price │
│ created_at │ │ quantity │ │ category │
└──────────────┘ │ total_amount │ └──────────────┘
│ status │
│ ordered_at │
└──────────────────┘
Normalization Levels:
1NF → No repeating groups
2NF → No partial dependencies
3NF → No transitive dependencies
Advantages of Normalization:
- No data duplication
- Easier updates (update in one place)
- Data integrity via constraints
- Storage efficient
Disadvantages:
- Complex JOINs for reads
- Performance overhead at scale
- Rigid schema changes
NoSQL: Denormalized Model
Data is stored together as it’s accessed, optimizing for read performance.
User Document (Embedded Data):
┌─────────────────────────────────────────────────────┐
│ USER DOCUMENT │
├─────────────────────────────────────────────────────┤
│ { │
│ "_id": "user_123", │
│ "username": "john_doe", │
│ "email": "[email protected]", │
│ "profile": { │
│ "name": "John Doe", │
│ "avatar": "https://..." │
│ }, │
│ "orders": [ ◄── Embedded │
│ { │
│ "product": { ◄── Denormalized │
│ "name": "Laptop", │
│ "price": 999.99 │
│ }, │
│ "quantity": 1, │
│ "status": "completed" │
│ } │
│ ] │
│ } │
└─────────────────────────────────────────────────────┘
→ Single read fetches everything needed
→ No JOINs required
→ Data may be duplicated across documents
Advantages of Denormalization:
- Faster reads (single query)
- Simpler queries
- Better horizontal scalability
- Flexible schema evolution
Disadvantages:
- Data duplication
- Harder updates (update in multiple places)
- Larger storage footprint
- Potential inconsistency
Deep Dive: Schema Design
SQL: Schema-on-Write
The schema is defined before writing data. Every row must conform.
-- Schema is enforced at write time
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL, -- Required
department VARCHAR(50) NOT NULL, -- Required
salary DECIMAL(10,2) CHECK (salary > 0), -- Constraint
hire_date DATE NOT NULL, -- Required
manager_id INTEGER REFERENCES employees(id) -- Self-referencing FK
);
-- This will FAIL ✗
INSERT INTO employees (id, name) VALUES (1, 'Alice');
-- Error: column "department" violates not-null constraint
-- This will SUCCEED ✓
INSERT INTO employees (name, department, salary, hire_date)
VALUES ('Alice', 'Engineering', 95000.00, '2024-01-15');
-- Schema change requires migration
ALTER TABLE employees ADD COLUMN phone VARCHAR(20);
-- All existing rows get NULL for phone
Implications:
- ✅ Data quality guaranteed at DB level
- ✅ Self-documenting structure
- ❌ Migrations can be slow on large tables
- ❌ Downtime risk during schema changes
NoSQL: Schema-on-Read
No enforced schema. The structure is interpreted when reading data.
// Document 1 - Full profile
{
"_id": "emp_001",
"name": "Alice",
"department": "Engineering",
"salary": 95000,
"hire_date": "2024-01-15",
"skills": ["Python", "Go", "Kubernetes"]
}
// Document 2 - Different structure, SAME collection ✓
{
"_id": "emp_002",
"name": "Bob",
"dept": "Marketing", // Different field name!
"compensation": { // Nested object instead of flat field
"base": 75000,
"bonus": 10000
},
"contract_type": "part-time" // Field doesn't exist in Doc 1
}
// Both documents coexist in the same collection
// Application code must handle variations
Implications:
- ✅ Zero-downtime schema evolution
- ✅ Each document can have unique fields
- ✅ Rapid prototyping and iteration
- ❌ Application must handle missing/varied fields
- ❌ Data quality is the developer’s responsibility
- ❌ Schema validation must be done in code (or optional DB-level validation)
Deep Dive: Scalability
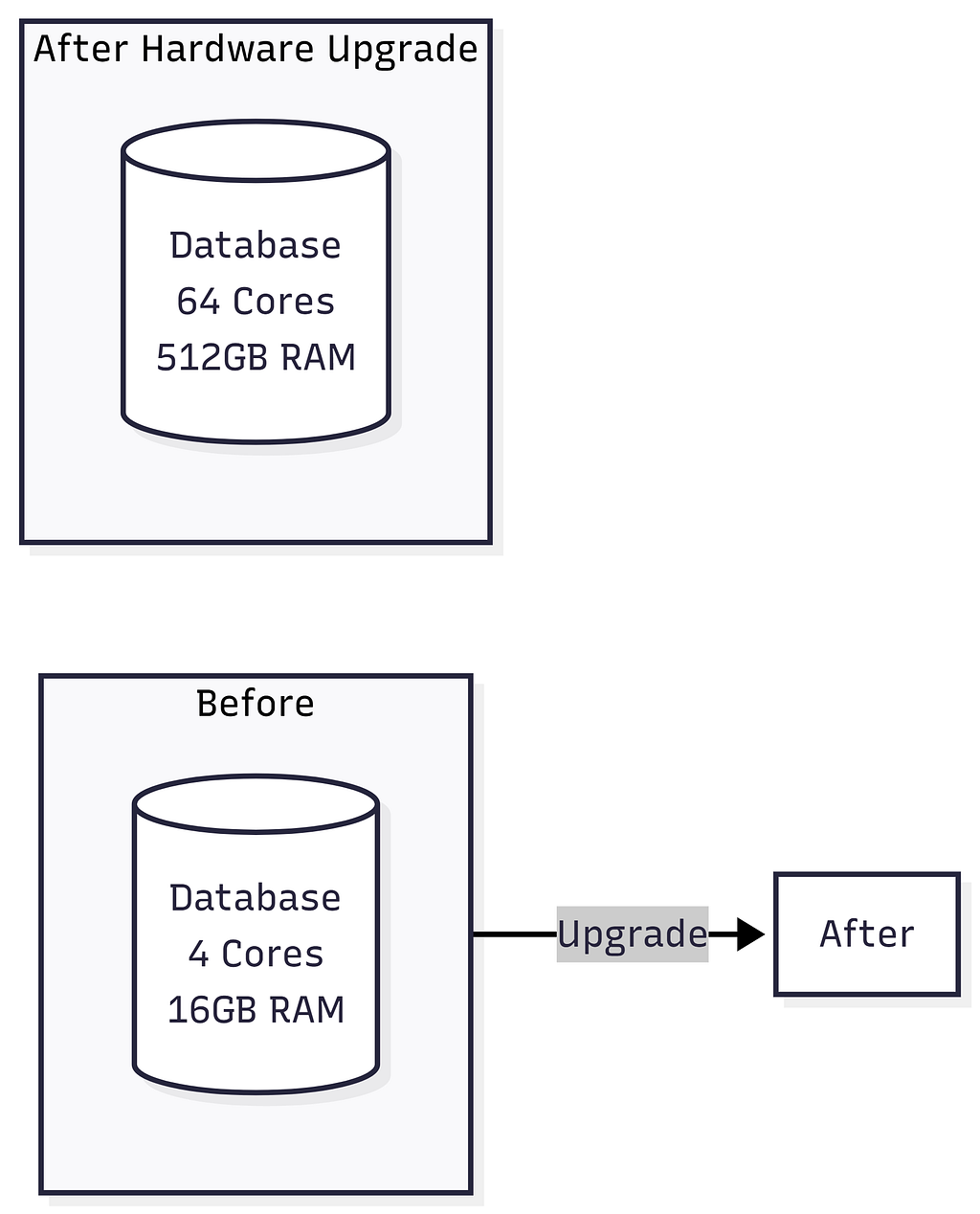
SQL traditionally relies on Vertical Scaling: Upgrading the server’s CPU, RAM, or Hard Drive. But you eventually reach a hardware limit — you simply can’t buy an infinitely powerful server. When you need Horizontal Scaling (buying 10,000 standard servers and distributing the data), SQL’s ACID guarantees and complex JOIN operations fall apart across multiple servers because querying across different machines is painfully slow.

Vertical Scaling (SQL — Scale Up)
SQL Read Scaling Options (Replication):

Horizontal Scaling (NoSQL — Scale Out)

Sharding Strategies:
- Hash-Based: hash(user_id) % num_shards = shard_id
- Range-Based: A-F → Shard1, G-N → Shard2, etc.
- Geographic: US → Shard1, EU → Shard2, Asia → Shard3
Scaling Comparison Summary:
Performance
▲
│ NoSQL (horizontal)
│ ╱
│ ╱
│ ╱ SQL (vertical)
│ ╱ ╱
│ ╱ ╱
│ ╱ ╱ ← Hardware ceiling
│ ╱ ╱ . . . . . . . . .
│ ╱ ╱
│╱ ╱
└──────────────────────────────────► Scale
Cost & Complexity
Key Insights:
- SQL (Vertical): Performance hits a hardware ceiling. You can’t scale beyond the biggest server available.
- NoSQL (Horizontal): Performance scales linearly by adding more commodity servers. No hard ceiling.
- Cost: SQL breaks exponential cost curve. NoSQL maintains linear cost scaling.
Deep Dive: ACID vs BASE
ACID (SQL Databases)
┌─────────────────────────────────────────────────────────────┐
│ ACID Properties │
├──────────────┬──────────────────────────────────────────────┤
│ │ │
│ Atomicity │ All operations succeed, or ALL roll back. │
│ │ "All or Nothing" │
│ │ │
│ │ BEGIN TRANSACTION; │
│ │ UPDATE accounts SET bal = bal - 100 │
│ │ WHERE id = 'Alice'; │
│ │ UPDATE accounts SET bal = bal + 100 │
│ │ WHERE id = 'Bob'; │
│ │ COMMIT; ← Both happen, or neither does │
│ │ │
├──────────────┼──────────────────────────────────────────────┤
│ │ │
│ Consistency │ Data moves from one valid state to another. │
│ │ All constraints, triggers, cascades hold. │
│ │ │
│ │ Total money before = Total money after │
│ │ Foreign keys always point to valid records │
│ │ │
├──────────────┼──────────────────────────────────────────────┤
│ │ │
│ Isolation │ Concurrent transactions don't interfere. │
│ │ Each transaction sees a consistent snapshot. │
│ │ │
│ │ Isolation Levels: │
│ │ READ UNCOMMITTED (lowest) │
│ │ READ COMMITTED │
│ │ REPEATABLE READ │
│ │ SERIALIZABLE (highest) │
│ │ │
├──────────────┼──────────────────────────────────────────────┤
│ │ │
│ Durability │ Once committed, data survives crashes. │
│ │ Written to disk / WAL (Write-Ahead Log). │
│ │ │
│ │ Power failure after COMMIT? Data is safe. ✓ │
│ │ │
└──────────────┴──────────────────────────────────────────────┘
ACID (SQL Databases)
┌─────────────────────────────────────────────────────────────┐
│ ACID Properties │
├──────────────┬──────────────────────────────────────────────┤
│ │ │
│ Atomicity │ All operations succeed, or ALL roll back. │
│ │ "All or Nothing" │
│ │ │
│ │ BEGIN TRANSACTION; │
│ │ UPDATE accounts SET bal = bal - 100 │
│ │ WHERE id = 'Alice'; │
│ │ UPDATE accounts SET bal = bal + 100 │
│ │ WHERE id = 'Bob'; │
│ │ COMMIT; ← Both happen, or neither does │
│ │ │
├──────────────┼──────────────────────────────────────────────┤
│ │ │
│ Consistency │ Data moves from one valid state to another. │
│ │ All constraints, triggers, cascades hold. │
│ │ │
│ │ Total money before = Total money after │
│ │ Foreign keys always point to valid records │
│ │ │
├──────────────┼──────────────────────────────────────────────┤
│ │ │
│ Isolation │ Concurrent transactions don't interfere. │
│ │ Each transaction sees a consistent snapshot. │
│ │ │
│ │ Isolation Levels: │
│ │ READ UNCOMMITTED (lowest) │
│ │ READ COMMITTED │
│ │ REPEATABLE READ │
│ │ SERIALIZABLE (highest) │
│ │ │
├──────────────┼──────────────────────────────────────────────┤
│ │ │
│ Durability │ Once committed, data survives crashes. │
│ │ Written to disk / WAL (Write-Ahead Log). │
│ │ │
│ │ Power failure after COMMIT? Data is safe. ✓ │
│ │ │
└──────────────┴──────────────────────────────────────────────┘
BASE (NoSQL Databases)
┌─────────────────────────────────────────────────────────────┐
│ BASE Properties │
├──────────────────┬──────────────────────────────────────────┤
│ │ │
│ Basically │ The system guarantees availability. │
│ Available │ Every request gets a response │
│ │ (success or failure), even during │
│ │ partial system failures. │
│ │ │
├──────────────────┼──────────────────────────────────────────┤
│ │ │
│ Soft State │ The state of the system may change │
│ │ over time, even without new input, │
│ │ due to eventual consistency. │
│ │ │
│ │ Node A: balance = $100 ←─┐ │
│ │ Node B: balance = $200 │ Converging │
│ │ Node C: balance = $200 ──┘ │
│ │ │
├──────────────────┼──────────────────────────────────────────┤
│ │ │
│ Eventually │ Given enough time and no new updates, │
│ Consistent │ all replicas will converge to the │
│ │ same value. │
│ │ │
│ │ t=0: Write "balance=200" to Node A │
│ │ t=1: Node A = 200, B = 100, C = 100 │
│ │ t=2: Node A = 200, B = 200, C = 100 │
│ │ t=3: Node A = 200, B = 200, C = 200 ✓ │
│ │ │
└──────────────────┴──────────────────────────────────────────┘
ACID vs BASE Comparison
ACID BASE
┌───────────┐ ┌───────────┐
│ Strong │ │ Eventual │
│Consistency│ │Consistency│
│ │ │ │
│ ✓ Banking │ │ ✓ Social │
│ ✓ Inventory│ │ media │
│ ✓ Healthcare│ │ ✓ Analytics│
│ │ │ ✓ Caching │
│ Higher │ │ Higher │
│ Latency │ │ Throughput│
└───────────┘ └───────────┘
When to Choose:
- ACID: Banking, Inventory, Healthcare systems (Higher Latency, guaranteed correctness)
- BASE: Social media, Analytics, Caching systems (Higher Throughput, eventual correctness)
Deep Dive: CAP Theorem
The CAP Theorem states that a distributed database can guarantee only two out of three properties simultaneously.
CAP THEOREM
(Choose 2 of 3 Properties)
▲
╱│╲
╱ │ ╲
╱ │ ╲
╱ │ ╲
╱ │ ╲
╱ CP │ AP ╲
╱ │ ╲
╱ │ ╲
╱========●========╲
╱ MongoDB Cassandra
╱ HBase DynamoDB
╱ Redis Cluster CouchDB
╱ ╲
╱____________________________╲
Consistency Availability
Partition Tolerance
(Always Present!)
⚠️ In distributed systems, network partitions WILL happen.
You must choose between:
CP: Sacrifice Availability → Reject writes during partition
AP: Sacrifice Consistency → Serve stale data during partition
CA: Single-node systems only (NOT viable in practice)
CAP Choices Explained:
┌──────────────────────────────────────────────────────────────┐
│ CP: Consistency + Partition Tolerance │
├──────────────────────────────────────────────────────────────┤
│ Examples: MongoDB, HBase, Redis (cluster) │
│ │
│ Strategy: When network partition occurs, BLOCK writes │
│ until partition heals. Ensures consistency. │
│ │
│ Tradeoff: Lower availability during network issues │
│ Use Case: Financial systems, banking (↑ consistency) │
└──────────────────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────────────────┐
│ AP: Availability + Partition Tolerance │
├──────────────────────────────────────────────────────────────┤
│ Examples: Cassandra, DynamoDB, CouchDB │
│ │
│ Strategy: When network partition occurs, ALLOW writes │
│ on both sides. Data converges when partition heals. │
│ │
│ Tradeoff: Temporary inconsistency (eventual consistency) │
│ Use Case: Social media, analytics (↑ availability) │
└──────────────────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────────────────┐
│ CA: Consistency + Availability (THEORETICAL) │
├──────────────────────────────────────────────────────────────┤
│ Examples: Traditional RDBMS (single node), SQLite │
│ │
│ Reality: These are NOT partition tolerant because they │
│ either crash or cannot replicate across networks. │
│ │
│ In modern cloud systems, CA doesn't exist in practice! │
└──────────────────────────────────────────────────────────────┘
⚠️ Important Insight:
In a distributed system, network partitions will happen. You cannot avoid the P in CAP. Therefore, the real-world choice is CP vs AP, not CA.
Types of NoSQL Databases
1. Document Stores
- Structure: JSON/BSON documents in collections
- Examples: MongoDB, CouchDB, Firestore
- Best For: Content management systems, User profiles, Product catalogs with varying attributes, Real-time analytics
{ "_id": 1,
"name": "iPhone 15",
"specs": { "storage": "256GB" },
"tags": ["smartphone", "apple"]
}2. Key-Value Stores
- Structure: Simple key → value pairs
- Examples: Redis, DynamoDB, Memcached
- Best For: Caching (sessions), Real-time leaderboards, Message queues, Rate limiting
3. Wide-Column Stores
- Structure: Rows with dynamic columns, grouped by column families. Optimized for writes.
- Examples: Cassandra, HBase, ScyllaDB
- Best For: Time-series data (IoT, metrics), Write-heavy workloads, Event logging
4. Graph Databases
- Structure: Nodes (entities) + Edges (relationships)
- Examples: Neo4j, Amazon Neptune
- Best For: Social networks, Fraud detection, Recommendation engines

NoSQL Types Comparison
https://medium.com/media/708be2b694c45cccb9a792581ea86994/hrefQuery Language & Flexibility
SQL: Standardized and Powerful
SQL is excellent for complex analytical queries, window functions, and recursive queries (CTEs).
SELECT
d.department_name,
COUNT(e.id) AS employee_count,
AVG(e.salary) AS avg_salary
FROM employees e
JOIN departments d ON e.department_id = d.id
WHERE e.status = 'active'
GROUP BY d.department_name
HAVING COUNT(e.id) > 5;
NoSQL: Database-Specific
MongoDB (Aggregation Pipeline):
db.orders.aggregate([
{ $match: { status: "completed" } },
{ $lookup: { from: "users", localField: "user_id", foreignField: "_id", as: "user" }},
{ $unwind: "$user" },
{ $group: { _id: "$user.country", totalRevenue: { $sum: "$amount" } }}
]);
Redis (Simple KV & Structures):
redis.set("user:1001:session", session_token, ex=3600) # TTL
redis.zadd("leaderboard", {"alice": 2500, "bob": 1800}) # Sorted SetNeo4j (Cypher for Relationships):
MATCH (user:Person {name: "Alice"})-[:FRIEND*1..3]-(fof:Person)
WHERE NOT (user)-[:FRIEND]-(fof) AND user <> fof
RETURN DISTINCT fof.name AS suggestionPerformance Considerations
Read Performance
https://medium.com/media/0758b2a09cf479e9c7a1a64583d23a3d/hrefWrite Performance
https://medium.com/media/7ba2807e084bb4e0aeec0e402565bd6b/hrefSQL Database Limitations
Understanding SQL’s limits helps you know when to reach for NoSQL.
1. Rigid Schema Problems
SQL databases enforce a fixed set of columns per row, which is great for consistent data but causes problems with highly variable data:
E-Commerce Products — Schema Problem:
┌──────────────────┬────────────────┬─────────────────┬──────────────┬──────────┐
│ product_id │ name │ screen_size │ boot_size │ RAM │
├──────────────────┼────────────────┼─────────────────┼──────────────┼──────────┤
│ laptop_001 │ MacBook Pro │ 14 inch │ NULL ← ❌ │ 16 GB │
│ boot_001 │ Hiking Boots │ NULL ← ❌ │ Size 10 │ NULL ← ❌│
└──────────────────┴────────────────┴─────────────────┴──────────────┴──────────┘
→ Sparse data causes many NULL values → ambiguity (Is NULL "not applicable" or "unknown"?)
→ NoSQL Document DBs solve this: each product document has only its own relevant fields
2. Thousands of Tables Problem
SQL databases are optimized for millions to billions of rows in a table, but not for thousands of tables:
❌ If your schema requires an unknown or massive number of tables, SQL will behave weirdly and get very slow.
3. Sharding Nullifies SQL Advantages
Sharding is the only solution for SQL when handling massive data or write traffic — but it destroys what makes SQL special:
https://medium.com/media/c80f50488e621f5942bcb83a9e397b20/href💡 Key Insight: If you need to shard, you’re likely better off with NoSQL from the start — it’s designed for sharding natively.
NoSQL Indexing & Query Mechanisms
Document Databases (MongoDB) — Index Internals
MongoDB Index Structure (B+ Tree):
┌─────────────────────────────────────────────────────────┐
│ B+ Tree Index on "hashtag" │
├──────────────┬──────────────────┬───────────────────────┤
│ Index Key │ Document Value │ Document ID (→ shard) │
├──────────────┼──────────────────┼───────────────────────┤
│ "apple" │ "Apple Inc" │ doc_001 │
│ "design" │ "UI Design" │ doc_004 │
│ "tech" │ "Technology" │ doc_003 │
└──────────────┴──────────────────┴───────────────────────┘
→ Query by index key → Get matching Document IDs → Fetch full document
→ MongoDB auto-indexes document ID; other fields need manual index creation
Querying without index = Full Collection Scan (very slow for large collections!)
// Slow: No index on "type" field
db.products.find({ type: "laptop" })
// Fast: After creating index
db.products.createIndex({ type: 1 })
db.products.find({ type: "laptop" })
// Slow: Compound query — needs both index + linear scan
db.messages.find({ group_id: "g123", timestamp: { $gt: "2024-01-01" } })
// → Index finds all docs with group_id="g123" → then linear scan by timestamp
🔑 Document databases automatically index every attribute (MongoDB does for doc ID). Other attributes require manually created indexes.
UUID v4 — Client-Generated IDs
MongoDB’s randomly generated UUID v4 allows the client to generate a unique ID without hitting the database, enabling massive write scalability:
import uuid
# Generate on the client side — no DB round-trip needed!
new_doc_id = str(uuid.uuid4()) # e.g., "550e8400-e29b-41d4-a716-446655440000"
# Insert without checking for ID collisions
# (collision probability is astronomically low)
db.messages.insert_one({
"_id": new_doc_id,
"group_id": "g123",
"content": "Hello!",
"timestamp": "2024-06-15T10:30:00Z"
})
✅ UUID v4 scales to trillions of documents without ever needing a centralized ID counter.
Column Family DB — Deep Dive
Column family databases (Cassandra, HBase) organize data in a unique way: every row can have different columns, making each row conceptually its own schema.
Column Family Database Structure:
┌──────────────────────────────────────────────────────────────────────┐
│ Row Key (Shard Key) │ Column Family: "messages" │
├──────────────────────┼──────────────────────────────────────────────┤
│ │ timestamp:content pairs (sorted by time) │
│ group_id_123 │ 2024-01-01T10:00 → "Hello!" │
│ │ 2024-01-01T10:05 → "How are you?" │
│ │ 2024-01-01T10:10 → "Great thanks!" │
├──────────────────────┼──────────────────────────────────────────────┤
│ group_id_456 │ 2024-01-02T14:00 → "Meeting at 3pm" │
│ │ 2024-01-02T14:30 → "Confirmed" │
└──────────────────────┴──────────────────────────────────────────────┘
→ Sharding is automatic based on Row Key (e.g., group_id)
→ Each row is like a separate table with its own schema
→ Fetching recent K messages = very fast (sorted by timestamp)
Twitter Hashtag Example — Column Family vs Document DB
This is a classic example illustrating why column family databases excel over document stores for certain patterns.
Option 1 — Document Database (MongoDB):
Problem: Slow compound queries
→ Index on hashtag + linear scan by timestamp = slow
→ For "Popular tweets" (sorted by likes): separate index needed
→ Challenge: Likes update frequently → massive index rewrites
Option 2 — Column Family Database (Cassandra):
Row Key = hashtag (e.g., "#Python")
Column Family: "recent_tweets"
└─ Key: timestamp → Value: "tweet_content | tweet_id"
(sorted by timestamp → fetch latest K tweets in O(1))
Column Family: "popular_tweets"
└─ Key: zero_padded_likes + tweet_content → Value: tweet data
(e.g., "0000001523 | Hello World" → sorted by likes count!)
└─ Prefix match query: Get top tweets by likes prefix efficiently
Cron Job (every 10-60 min):
→ Re-insert popular tweets with updated like counts
→ Drop oldest entries if column exceeds 1000 values
Example Stored Values:
┌──────────────────┬──────────────────────────────────────────────┐
│ Row Key │ popular_tweets column (sorted) │
├──────────────────┼──────────────────────────────────────────────┤
│ #Python │ "0000051234|tweet_abc" → {...} │
│ │ "0000023456|tweet_xyz" → {...} │
│ │ "0000001001|tweet_pqr" → {...} │
└──────────────────┴──────────────────────────────────────────────┘
→ Prefix match on "000005" returns all tweets with 5xxx likes
→ Efficient "top tweets" queries without expensive sorts!
Real-World Column Family Use Cases
https://medium.com/media/905682ddf44b28007afb823d35bb3bf5/hrefSharding Key Selection Strategies
Choosing the right sharding key is the most critical decision in distributed systems design. A bad sharding key leads to hotspots, uneven load, and cross-shard query nightmares.
The Golden Rules of Sharding Key Selection
Good Sharding Key Criteria:
✅ Even load distribution across shards
✅ Most frequent queries touch only ONE shard
✅ Minimizes cross-shard writes
✅ Avoids hotspots (no single "super popular" key)
✅ Granularity matches data volume (too coarse → hotspots, too fine → overkill)
Example 1: Messaging App (WhatsApp DMs)
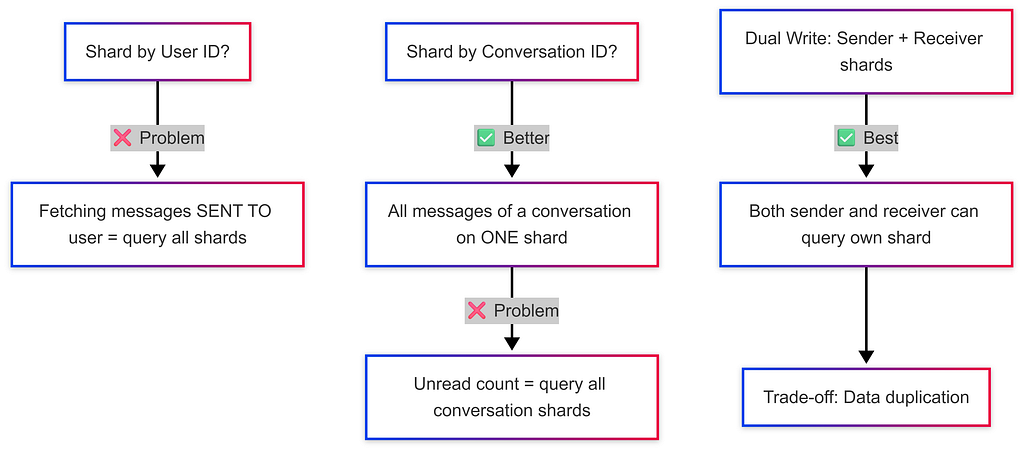
Example 2: Banking System (Transactions)
Sharding Key Options:
❌ Account ID → Too granular; a user with many accounts is spread across shards
❌ City ID → Users change cities → data migration nightmare + uneven load (big cities = hotspots)
✅ User ID → Simple balance queries, transaction history all on ONE shard
Tricky Case: Transferring Money Between Users
→ Sender shard ≠ Receiver shard
→ Requires DISTRIBUTED TRANSACTION (see next section)
→ Solution: Application server acquires locks on both shards, executes, then releases
Example 3: Ride-Sharing App (Uber)
Finding Nearby Drivers:
❌ Shard by User ID → Driver could be anywhere; "find nearby drivers" = query all shards
❌ Shard by Driver ID → Same problem as User ID
✅ Shard by City ID → All drivers in Paris are on the Paris shard → one shard query!
Intercity Rides:
→ Only query the SOURCE city shard for drivers
→ Drivers must be AT the source city, not destination
Sharding Granularity:
→ Small cities (population 100K) → one shard for entire city
→ Large cities (Beijing, Mumbai) → multiple shards per city (based on back-of-envelope estimates)

Example 4: Ticket Booking (IRCTC)
Problem: Preventing Double Bookings
❌ Shard by User ID:
→ 2 users book the same train simultaneously
→ Both queries go to different user shards
→ NO coordination between shards → double booking!
❌ Shard by Date:
→ Today's / tomorrow's bookings overload the "date" shard
→ Hot shard problem
✅ Shard by Train ID:
→ All bookings for Train #12301 go to the SAME shard
→ Database handles concurrent booking locks automatically
→ No double booking possible within a shard!
IRCTC Table Architecture (real scale: ~10M bookings/year):
https://medium.com/media/113cec2743f2cfbdd0794dd0be7e5099/hrefSharding Key Decision Framework
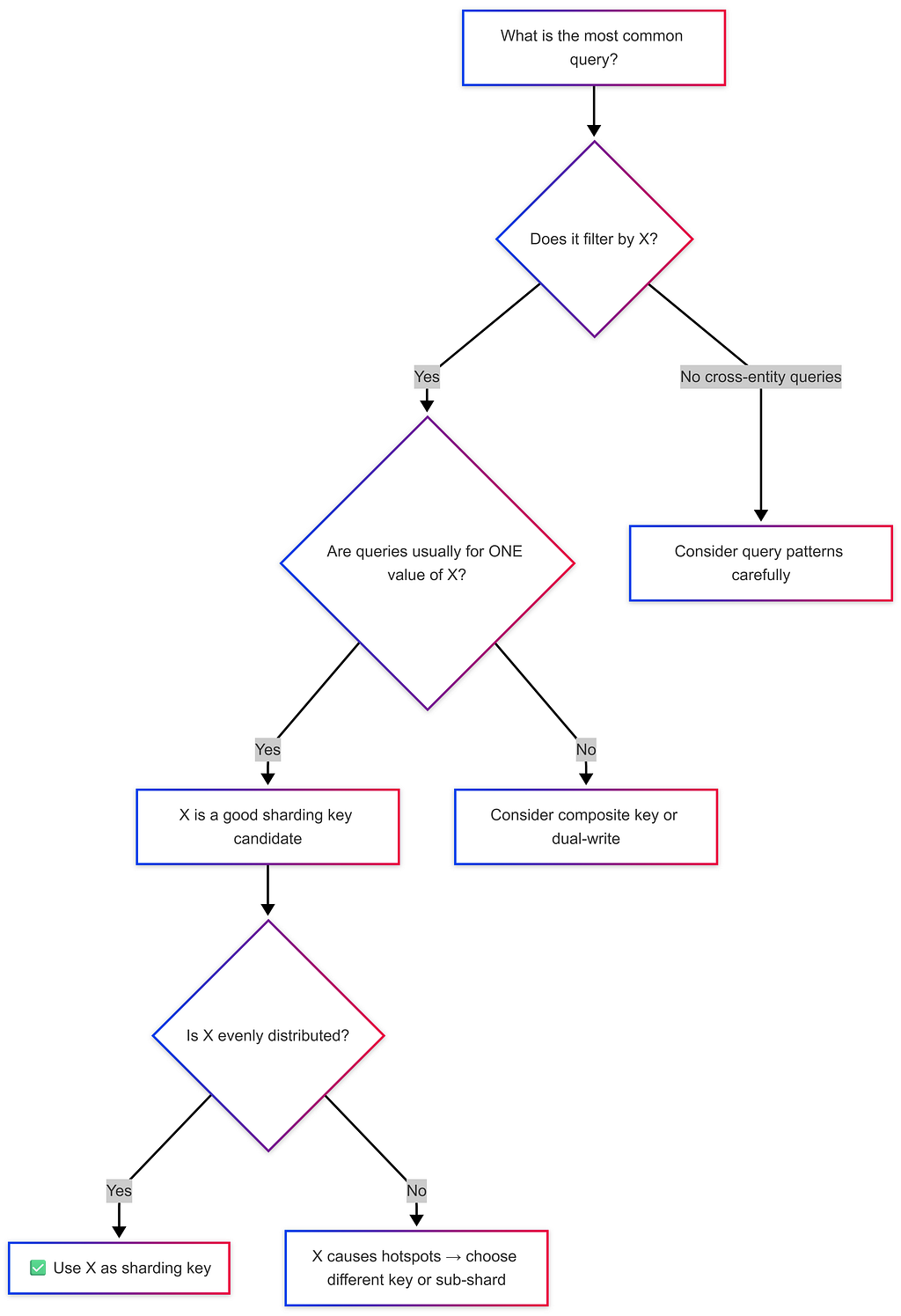
💡 Back-of-Envelope: Always estimate shard load. If one shard is expected to store 10× more data than others, you have a hotspot problem.
Distributed Transactions & Cross-Shard Operations
The Problem
When data related to one operation lives on different shards, maintaining ACID guarantees becomes the developer’s responsibility — not the database’s.
Cross-Shard Transaction Example (Banking):
Shard 1 (Alice's data): Shard 2 (Bob's data):
┌────────────────────────┐ ┌────────────────────────┐
│ Alice: $1000 │ │ Bob: $500 │
└────────────────────────┘ └────────────────────────┘
Transfer $100 from Alice → Bob:
1. App Server: Lock Alice's row on Shard 1 ← acquire lock
2. App Server: Lock Bob's row on Shard 2 ← acquire lock
3. Deduct $100 from Alice → COMMIT Shard 1
4. Add $100 to Bob → COMMIT Shard 2
5. App Server: Release both locks
⚠️ If Step 4 fails after Step 3 committed → money vanishes!
Developer must implement rollback logic manually.
Distributed Transaction Approach
Two-Phase Commit (2PC):https://medium.com/media/664780eb38992a3c8f070c0223c7080d/href
Phase 1 — PREPARE:
→ Ask all shards: "Can you commit this change?"
→ Each shard locks data and replies YES/NO
Phase 2 — COMMIT (if all YES) / ABORT (if any NO):
→ All shards commit together
→ Or all shards roll back
⚠️ Drawbacks:
→ High latency (multiple network round-trips)
→ Single coordinator failure can leave shards in limbo (blocking protocol)
💡 Best Practice: Design your sharding key so that the most critical operations (like bookings, transfers) happen within a single shard, avoiding distributed transactions whenever possible.
When to Use SQL
✅ Choose SQL When:
- Data Integrity is Critical: Banking, healthcare, financial transactions (ACID requirements).
- Complex Queries & Reporting: Business intelligence run aggregations across multiple tables.
- Structured, Predictable Data: Well-defined entities where schema rarely changes.
- Moderate Scale: Up to ~10TB or millions of records (not billions).
- Strong Ecosystem Needed: Mature ORMs, tooling, and huge talent pool.
Real SQL Use Cases: E-commerce orders, ERP/CRM, Healthcare records, Accounting.
When to Use NoSQL
✅ Choose NoSQL When:
- Massive Scale / High Throughput: Billions of records, >100K ops/sec, globally distributed.
- Flexible / Evolving Schema: Rapid prototyping, varied record types in one collection.
- Specific Data Access Patterns: Time-series logs, graph traversals, simple KV caches.
- High Availability Priority: 99.999% uptime via partition tolerance over consistency.
- Denormalized Read-Heavy Workloads: User feeds, CMS, catalogs.
Real NoSQL Use Cases: Session management (Redis), IoT sensor data (Cassandra), Chat/messaging (Cassandra), Recommendation graphs (Neo4j).
Real-World System Design Examples
Example 1: E-Commerce Platform
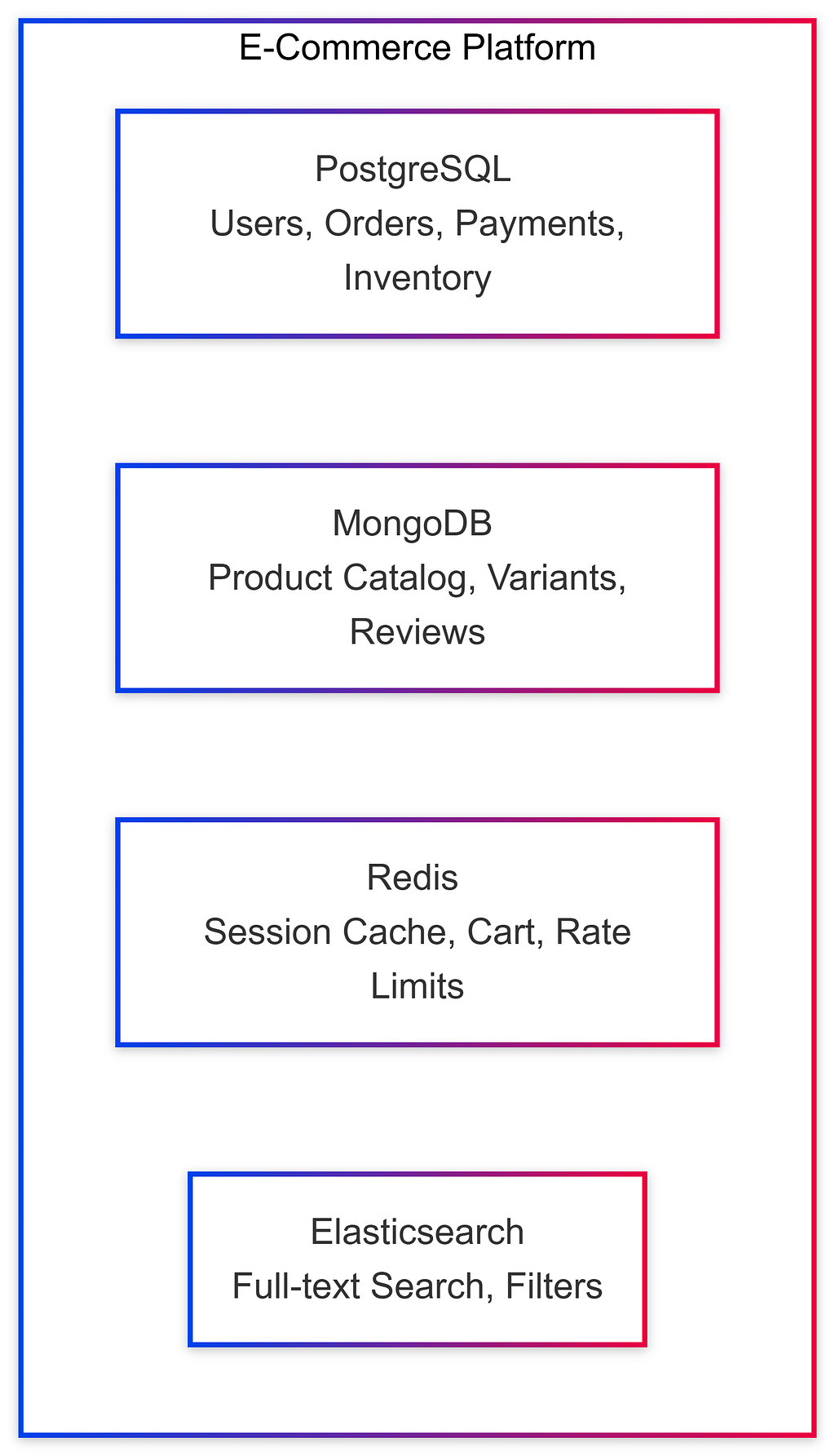
Example 2: Social Media Platform (Twitter-like)
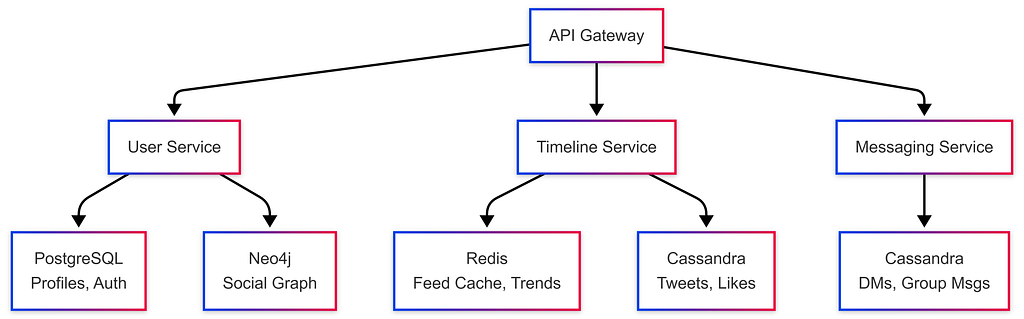
Example 3: Uber-like Ride Sharing
https://medium.com/media/6d3ffdb4d54d2c3e8ed9ae82f8106415/hrefGroup Chat Systems Architecture
Group chat systems (Slack, WhatsApp, Discord) present unique database and scalability challenges at scale.
Data Model
-- Core tables for a group chat system
TABLE users -- user_id, name, email, ...
TABLE groups -- group_id, name, created_at, ...
TABLE group_members -- group_id, user_id, joined_at, ...
TABLE group_messages -- message_id (sharding key), group_id, sender_id, content, timestamp
TABLE message_reads -- message_id, user_id, read_at (tracks who saw what)
Sharding Strategy for Group Messages
Shard by Group ID:
→ All messages for a group live on ONE shard → efficient pagination
→ No need to copy messages to each user's shard (even for groups with 100K members!)
Database Recommendation:
→ Column Family DB (Cassandra):
Row Key = group_id
Columns = timestamp → message_content (sorted by time → fetch recent K messages fast)
→ Document DB (MongoDB):
Each message = one document with message_id as document ID
Real-Time Delivery Architecture
When a message is sent to a group with 100,000 members:
Message → App Server → Queue (Kafka) → Consumers → WebSocket servers → Online users
Step-by-step:
1. Sender sends message via WebSocket
2. App server saves message to DB (shard by group_id)
3. App server publishes to Kafka topic
4. Consumer workers pull from Kafka and push to online members via WebSocket
5. Offline users fetch messages when they reconnect (paginated query on group_id shard)
⚠️ For groups with 1 BILLION subscribers (e.g., a celebrity):
→ Kafka acts as "shock absorber" — all notifications processed over hours, not seconds

Slack vs WhatsApp: Different Design Choices
https://medium.com/media/a8aa2cc6eaffd87dbe557e5a4055117c/hrefCaching Strategies
Caching stores frequently accessed data in a fast layer (usually Redis / in-memory) between the user and the database.
Without Cache: With Cache:
User → App Server → DB (slow) User → App Server → Cache (fast!) ✓
↑ miss
App Server → DB → Update Cache
Cache Hit vs Cache Miss
def get_user(user_id):
# Try cache first
cached = redis.get(f"user:{user_id}")
if cached:
return cached # ✅ Cache hit — fast!
# Cache miss — query DB
user = db.query("SELECT * FROM users WHERE id = ?", user_id)
redis.set(f"user:{user_id}", user, ttl=3600) # Store in cache
return user
Negative Caching
Cache even when there are no results — to avoid repeated expensive DB queries for missing data:
def get_movie(movie_id):
cached = redis.get(f"movie:{movie_id}")
if cached == "NOT_FOUND":
return None # Negative cache hit — don't hit DB again!
if cached:
return cached
movie = db.query("SELECT * FROM movies WHERE id = ?", movie_id)
if movie is None:
redis.set(f"movie:{movie_id}", "NOT_FOUND", ttl=300) # Cache the miss!
return None
redis.set(f"movie:{movie_id}", movie, ttl=3600)
return movie
💡 Use Case: Netflix caching unavailable content IDs. Without negative caching, millions of “Does movie X exist?” queries hit the DB even though the answer is always “No.”
Cache Write Strategies
Write-Through Cache:https://medium.com/media/e1fb16cca01fec02ccb2de4c680e1bf5/href
User → App Server → [DB + Cache simultaneously]
✅ Cache always up-to-date
❌ Higher write latency (must wait for both)
Write-Behind (Write-Back) Cache:
User → App Server → [Cache immediately] → [DB later via background job]
✅ Lower write latency
❌ Risk of data loss if cache crashes before DB sync
Read-Through Cache:
User → App Server → Cache → [on miss] → DB → update Cache
✅ Transparent to application
❌ First request is always slow (cold cache)
Cache-Aside (Lazy Loading): ← Most common
Application manually checks cache, queries DB on miss, populates cache
✅ Flexibility — only cache what's needed
❌ Application code is responsible for cache consistency
Client-Side Caching
For reducing server/database load further:
// React Query (TanStack Query) — client-side cache
const { data: notifications } = useQuery({
queryKey: ['notifications', userId],
queryFn: () => fetchNotifications(userId),
staleTime: 60_000, // Data fresh for 60 seconds
cacheTime: 300_000, // Keep in memory for 5 minutes
refetchOnWindowFocus: false // Don't refetch on every tab switch
});
// → Stored in-memory (or localStorage / IndexedDB)
// → Deduplicates multiple simultaneous requests automatically
Read-Heavy vs Write-Heavy Scalability
Read-Heavy System (small data):
→ Add Cache Layer → Cache serves 90%+ of reads → DB load drops dramatically
→ Example: Netflix movie metadata, Twitter trending topics
Write-Heavy System (large data):
→ Sharding required to distribute write load across multiple nodes
→ Combine with replication for read scaling:
Write → Master Shard → replicated to Slave Shards → Reads from slaves
Most Complex (but usually overkill):
→ Multiple shards, each with their own replicated cache layer
Notification System Scaling
Notification systems have wildly different requirements depending on scale. Use back-of-envelope estimates to choose the right architecture.
Scale Tier 1 — Small System (~1000 users)
Architecture: PostgreSQL (single table)
Table: notifications (notification_id, user_id, content, seen: bool, created_at)
→ Simple INSERT/UPDATE queries
→ WebSocket connection to push real-time notifications
→ No sharding, no Kafka needed
Scale Tier 2 — Medium System (100K instructors, 10M students)
Scenario: Instructor updates course content → 300,000 students must be notified
Architecture:
Instructor update → App Server → Kafka (producer)
↓
[Kafka Topic: course-updates]
↓
Consumer workers (read Kafka) → Push notifications to users
→ WebSocket for online users
→ DB for offline users (fetch on next login)
Scale Tier 3 — Massive System (1M channels, 500M users, ~1000 subscriptions/user)
Back-of-Envelope:
→ Users: 500M
→ Avg subscriptions per user: 1000 channels
→ Notification page views: 10×/day per user
→ Events per day: 500M users × 10 views = 5 BILLION events/day
Architecture:
→ Shard notifications by user_id (each user's notifications in one place)
→ Kafka as event bus between services
→ WebSockets for real-time push (WhatsApp handles 2M+ connections per server)
→ "Shock absorber" pattern for viral content (notifications processed over time, not instantly)
WebSocket Tracking:
→ WebSocket alone is insufficient — must persist "seen" status to DB
→ Combine: WebSocket delivery + DB persistence (notification_id, user_id, seen_at)
Hybrid Approaches (Polyglot Persistence)
Modern systems rarely use a single database. Polyglot Persistence means using the right database for each specific need.
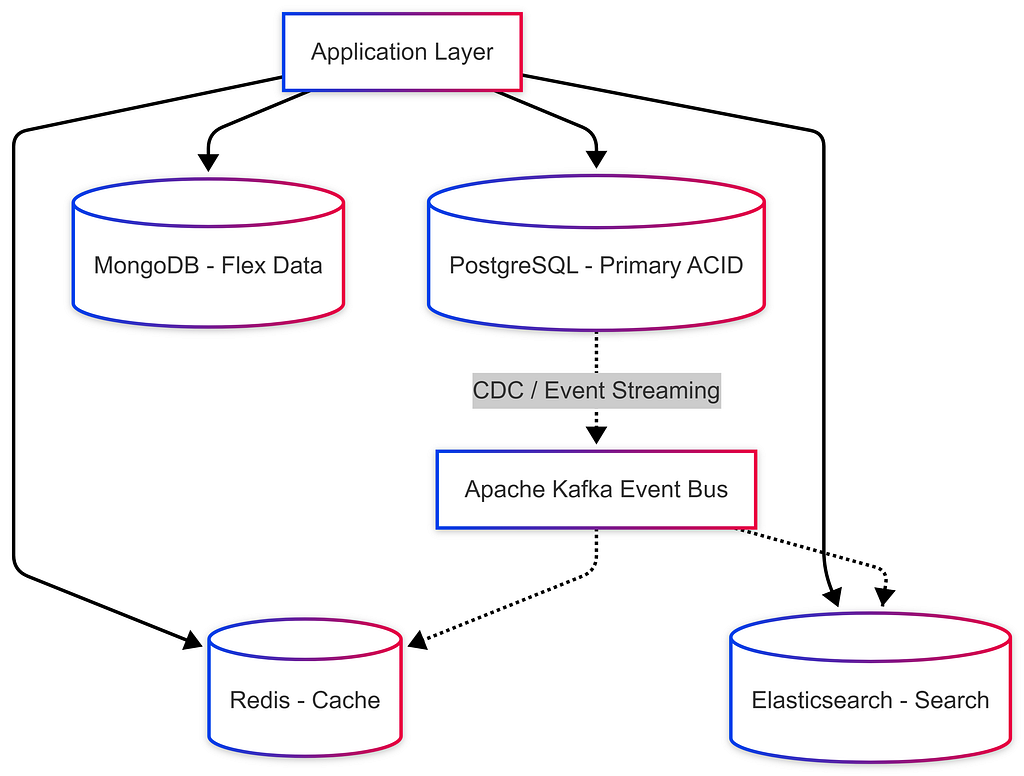
Common Synchronization Patterns:
- Change Data Capture (CDC): PostgreSQL → Debezium → Kafka → Elasticsearch / Redis.
- Dual Writes: App writes to PostgreSQL and Redis (Requires caution for consistency).
- Event Sourcing: Event Bus (Kafka) acts as source of truth and pipes read model to SQL/NoSQL.
Migration Strategies
SQL → NoSQL Migration Phases:
- Identify Pain Points: Scaling limits? Complex Schema changes?
- Data Modeling Change: Shift from Normalized (linking tables) to Denormalized (embedding array of addresses into user document).
- Gradual Rollout:
- Phase 1: Shadow writes (write to both SQL and NoSQL)
- Phase 2: Shadow reads (validate NoSQL against SQL)
- Phase 3: Switch reads to NoSQL
- Phase 4: Stop writes to SQL / Decommission.
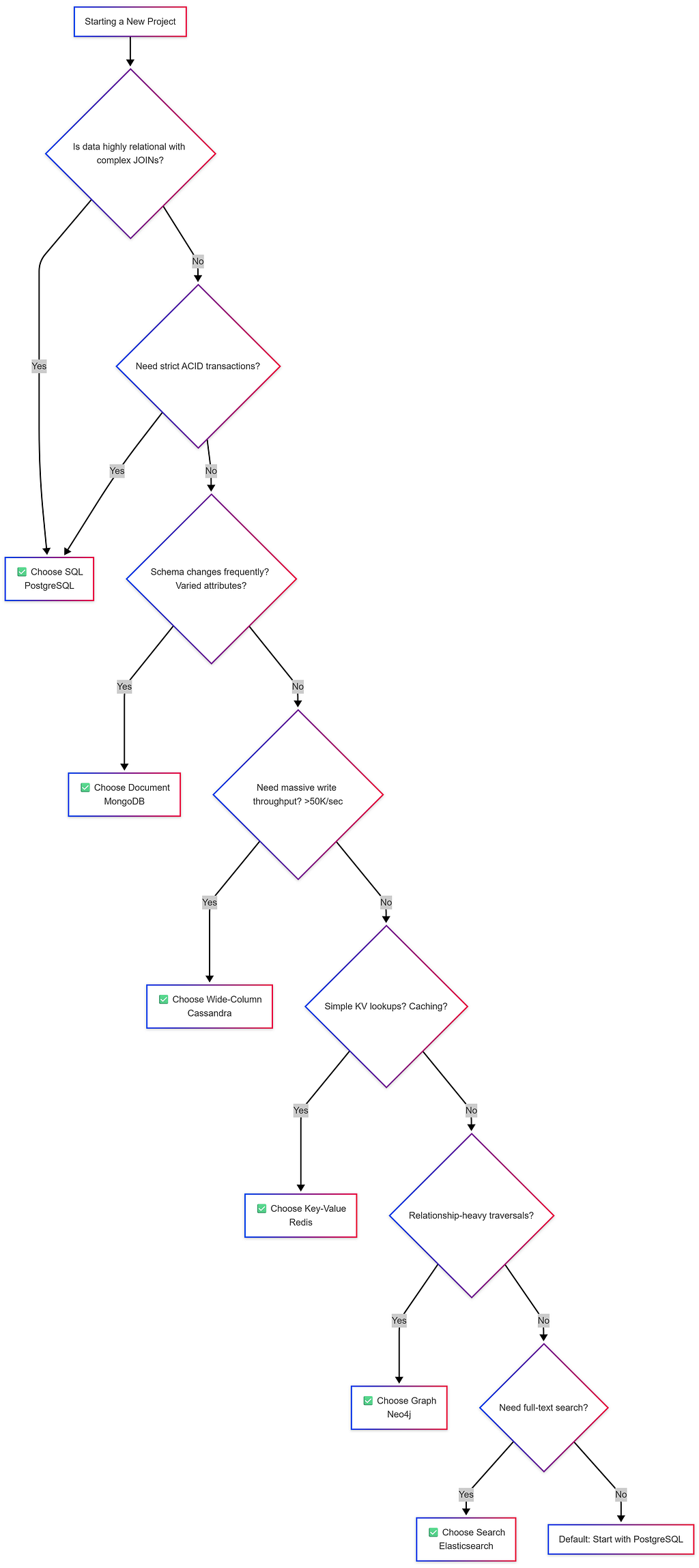
Decision Framework Flowchart
Common Interview Questions
Q1: “How would you choose between SQL and NoSQL for a new project?”
- Understand Data: Structured vs Semi-structured? Schema evolution?
- Understand Access Patterns: Read vs Write heavy? Simple lookups vs Complex Joins?
- Understand Scale: GBs vs TBs vs PBs? Growth projections?
- Understand Constraints: Consistency (Strong vs Eventual), team expertise.
- Default: Start with PostgreSQL, add Redis for caching. Polyglot Persistence.
Q2: “Can you use SQL at massive scale?”
- YES: Read replicas, Connection Pooling (PgBouncer), Partitioning, Sharding (Citus), Caching layers, Denormalization.
- Examples: Instagram (PostgreSQL for billions of rows), Shopify (MySQL).
Q3: “What are the drawbacks of NoSQL?”
- No standardized query language (steep learning curves).
- Application-level JOINs equal application complexity.
- Data integrity is entirely the developer’s responsibility.
- Over-engineering risk (Using NoSQL when PG would suffice).
Q4: “Design a URL shortener — which database?”
- Primary Store: PostgreSQL or DynamoDB (if expecting massive global scale).
- Caching Layer: Redis (Top 20% URLs serve 80% traffic).
- Analytics: Cassandra (append-only click logging).
Summary & Cheat Sheet
https://medium.com/media/0c98615f1ce93f61177e9bdb1c052f05/hrefGolden Rules:
- “When in doubt, start with PostgreSQL.” (Handles 80% of use cases).
- “Use the right tool for the job.” Polyglot Persistence is the norm.
- “Understand your access patterns FIRST.” NoSQL is query-driven; SQL is model-driven.
- “Consistency vs. Availability.” Banking? Choose CP/SQL. Social feed? Choose AP/NoSQL.
🤖 Orchestrators & Managing Hardware

An Orchestrator is the “Manager” of a distributed system. It knows exactly which servers are alive, dead, or idle, and routes traffic accordingly to prevent bottlenecks.
Orchestrator vs Kubernetes
https://medium.com/media/01f4298c24a99c9f6c88b8509c81692f/hrefReplicas vs Hot Copies
- Replica: A backup worker copying data (stateful). If a hard drive crashes, we don’t lose user data.
- Hot Copy: A manager-in-training (stateless). Has no hard drive data but perfect memory of the Orchestrator’s internal state. If the Orchestrator crashes, the Hot Copy takes over instantly (< 1 second lag).
- Idle Machine: Spare machine assigned as extra replica with a “reclaim contract” — can be taken back to replace a failed machine anytime.
Orchestrator Responsibilities (Full Lifecycle)

Why keep backups? If you selfishly create new shards using all available servers, the next time a server’s hard drive breaks, you’ll have zero replacements — immediate data loss.
Machine Addition Protocol
Scenario: 3 shards (S1, S2, S3), replication factor = 3, 3 new machines arrive
Step 1: Replace any downed machines first (highest priority)
Step 2: Calculate backup limit X = 1.5 × avg machines normally down (based on history)
Step 3: Place X machines in idle standby
Step 4: If remaining machines ≥ replication factor (3) → create new shard
Step 5: Any leftover machines become extra replicas of existing shards (reclaim contract)
Minimum requirement: Need at least 3 machines (replication factor) to create 1 new shard.
⚠️ Stateless machines (load balancers, app servers) don’t need replicas — just health checks + auto-restart. Stateful machines (database nodes) require replicas to prevent data loss.
Consistent Hashing & Load Distribution
Consistent hashing is the algorithm that determines which shard stores which data in a distributed database.
Traditional Hashing Problem:
hash(user_id) % 3 shards = shard assignment
→ Add a 4th shard: hash(user_id) % 4 ≠ same as % 3
→ EVERY key remaps to a different shard → massive data movement!
Consistent Hashing Solution:
→ Place shards and data keys on a virtual "ring" (0 → 2^32)
→ hash(user_id) → point on ring → assigned to nearest shard clockwise
→ Add new shard: only keys between new shard and previous shard remapped
→ Remove shard: only that shard's keys move to next shard clockwise
Consistent Hash Ring:
0
/ \
Shard3 Shard1
\ /
Shard2
360°
User A (hash=90°) → Shard1
User B (hash=200°) → Shard2
User C (hash=310°) → Shard3
Add Shard4 at 150°:
→ Only users between 90°-150° move to Shard4 (minimal disruption!)
Consistent Hashing + Replication
For replication factor = 3:
→ Each key is stored on the 3 nearest clockwise shards
→ Writes go to all 3 (based on tunable consistency settings)
→ Reads can come from any of the 3
Orchestrator maintains routing table:
key range → [primary shard, replica1, replica2]
Hot Shard Detection & Capacity Planning
Identifying Hot Shards
A hot shard is a shard receiving disproportionately more traffic than others, causing performance degradation.
Detection Signals:
→ Memory/disk utilization > threshold (e.g., 80%) on one shard
→ Write latency spikes on specific shard
→ CPU consistently high on one machine vs. others
Response:
[Hot Shard Detected] → Split shard into 2 → Assign new server to one half

Proactive Capacity Planning
❌ Don’t react to peak load — it’s too late. ✅ Do preemptively add servers based on historical load trends and projections.
Good Capacity Planning:
1. Monitor memory/disk utilization trends over weeks/months
2. Identify growth pattern (linear? exponential?)
3. Add servers BEFORE you hit 70% threshold — allows time for data migration
4. Plan sharding granularity based on data volume projections:
→ Small city (100K users) → 1 shard
→ Large city (10M users) → multiple shards
→ Use back-of-envelope: 1 shard ≈ 1TB data → project growth → plan shards
Multi-Master Replication & Tunable Consistency
Master-Slave vs Multi-Master Architecture
Master-Slave Architecture:
→ One designated MASTER handles all writes
→ Slaves replicate from master and serve reads
→ Failover: if master dies, promote a slave to master
→ Used by: MySQL, PostgreSQL, MongoDB (default)
✅ Simple, easy to reason about
❌ Master is bottleneck for writes
❌ Failover causes brief downtime
Multi-Master Architecture (Cassandra, DynamoDB):
→ Every node can accept writes (all are "master")
→ Writes replicated to neighbors on consistent hash ring
→ No single point of failure for writes
→ Used by: Cassandra, DynamoDB, CouchDB
✅ No write bottleneck, truly distributed
✅ Higher availability (no master election needed)
❌ Conflict resolution needed (concurrent writes to same record)
❌ More complex to reason about consistency
Tunable Consistency: The R+W Quorum System
Cassandra and DynamoDB allow you to configure how many replicas must respond for a read or write to be considered successful.
Configuration:
X = Replication Factor (number of copies of data)
W = Write Quorum (minimum replicas that must confirm a write)
R = Read Quorum (minimum replicas that must respond to a read)
Rule for Strong Consistency: R + W > X
Example: Replication factor X = 3
https://medium.com/media/340e3fa440aca7b854481f8c4189693c/hrefStrong Consistency Guarantee (R + W > X):
→ When reading R replicas, at least one MUST have the latest write
→ Even if some replicas are lagging, the quorum overlap guarantees freshness
Example: X=10, W=6, R=5 → R+W=11 > 10
→ Any 5 nodes we read from MUST include at least 1 of the 6 nodes we wrote to
→ Guaranteed to see the latest data ✅
Eventual Consistency (R + W ≤ X):
Example: X=3, W=1, R=1
→ Write goes to 1 node
→ Read might hit a DIFFERENT node (not yet replicated)
→ Stale read possible — data becomes consistent "eventually"
Conflict Resolution in Multi-Master:
When two clients write to the same key simultaneously:
→ Last Write Wins (LWW): Cassandra uses wall-clock timestamps
→ If different servers return different values, the one with the LATEST timestamp wins
→ Vector Clocks: Track causality (more complex, more correct)
→ Application-Level Merge: App decides how to combine conflicting values
⚙️ Cassandra Configuration: X, R, and W values are set in the Cassandra cluster configuration file when spinning up the cluster — not in application code.
Read from Multiple Replicas Pattern
# Read from R=3 replicas, take the value with the latest timestamp
responses = await asyncio.gather(
read_from_replica(key, node_1),
read_from_replica(key, node_2),
read_from_replica(key, node_3),
)
# Merge: pick response with highest timestamp
latest = max(responses, key=lambda r: r.timestamp)
return latest.value
Write-Ahead Logs (WAL)
Write-Ahead Logs are a fundamental mechanism that databases use to ensure durability and atomicity — a crucial concept that appears in both SQL and NoSQL systems.
How WAL Works
Without WAL:
→ DB modifies data structures on disk directly
→ Power failure mid-operation → inconsistent state!
With WAL:
→ ALL changes are first written to the WAL (append-only log on disk)
→ THEN applied to actual data structures
→ If power fails during write → replay WAL on restart → consistent state ✓
WAL Entry Structure:
┌─────────────────────────────────────────────────────────────┐
│ LSN (Log Sequence Number) │ Transaction ID │ Operation │
│ Timestamp │ Table/Key │ Before/After│
├─────────────────────────────────────────────────────────────┤
│ 001 │ txn_42 │ UPDATE accounts SET balance=900 │
│ │ │ WHERE id='alice' [before: 1000] │
│ 002 │ txn_42 │ UPDATE accounts SET balance=1100 │
│ │ │ WHERE id='bob' [before: 1000] │
│ 003 │ txn_42 │ COMMIT │
└─────────────────────────────────────────────────────────────┘
→ If crash after 002, before COMMIT → rollback both changes on restart
→ If crash after COMMIT → replay both changes on restart → consistent!
WAL Use Cases
https://medium.com/media/e1343059c5298236e165f56c06d32ed7/hrefWAL in Shard Migration
Two-Phase Data Migration uses WAL to prevent data loss:
Phase 1 — STAGING (background copy):
→ Orchestrator simulates new shard's key range
→ Starts copying existing data to new shard (background)
→ New shard NOT yet serving requests
→ All writes still go to old shard → captured in write-ahead log
Phase 2 — CUTOVER (go live):
→ Initial data copy complete
→ New shard added to consistent hash ring → starts serving requests
→ Replay WAL entries (writes that happened during Phase 1) to sync new shard
→ Brief period of potentially stale data → WAL replay catches up
→ New shard fully in sync ✅

Data Migration Process (Two-Phase)
When adding new shards or resharding, data must be migrated with zero downtime and zero data loss.
The Two-Phase Migration
Phase 1: STAGING
┌────────────────────────────────────────────────────────┐
│ 1. Orchestrator calculates new shard's key range │
│ 2. Begins copying data from source shard (background) │
│ 3. New shard NOT advertised to clients yet │
│ 4. All client reads/writes continue to old shard │
│ 5. New writes during copy → captured in WAL │
└────────────────────────────────────────────────────────┘
Phase 2: CUTOVER
┌────────────────────────────────────────────────────────┐
│ 1. Initial data copy complete │
│ 2. New shard added to routing table (consistent ring) │
│ 3. New shard starts serving requests immediately │
│ 4. WAL replay: apply writes from Phase 1 to new shard │
│ 5. Brief stale reads possible (WAL replaying in bg) │
│ 6. Once WAL fully replayed → full consistency │
└────────────────────────────────────────────────────────┘
Stateless vs Stateful Machine Failover
Stateless Machines (Load Balancers, App Servers):
→ No persistent data → no replica needed
→ Health check detects failure → spin up new instance (< 30 seconds)
→ Example: if a web server crashes, auto-scaling brings up a replacement
Stateful Machines (Database Nodes):
→ Persistent data → must copy data to replacement
→ Hot copy: Another machine has the SAME in-memory state
→ Failover in < 1 second (no cold start)
→ Warm replica: Has disk data but not in-memory state
→ Failover takes seconds to minutes (load data from disk to memory)
→ Cold backup: Just disk data, no memory state
→ Slowest failover — must copy data then load
Architecture Evolution Principles
Real systems don’t get built perfectly from day one. Here’s how to think about evolving your database architecture over time.
Why Requirements Change
Common triggers for re-architecture:
→ Data volume 10×-100× growth
→ New query patterns (e.g., adding analytics to a transactional system)
→ User behavior changes (write-heavy → read-heavy, or vice versa)
→ Geographic expansion (need geo-sharding)
→ Regulatory requirements (data residency)
When to Re-Architect

The Dual-Write Migration Pattern
When changing sharding keys or moving between databases:
Step 1: Dual-write — new writes go to BOTH old and new system
Step 2: Backfill — copy historical data from old to new
Step 3: Validate — compare queries on old vs new
Step 4: Gradual traffic shift — 1% → 10% → 50% → 100% to new system
Step 5: Decommission old system
Key Principles
- Start simple. Start with PostgreSQL. Add complexity only when needed.
- Back-of-envelope first. Always estimate before architecting: how many users? How much data? How many writes/second?
- Optimize for the common case. Design sharding key for the most frequent query, not the edge case.
- Avoid cross-shard operations. Design a data model so that critical transactions happen within one shard.
- Anticipate changes. When designing, think: “What if this data 10×? What if we add feature Y?” — plan escape hatches.
- Don’t over-engineer. A notification system for 1000 users does NOT need Kafka + sharding. Match complexity to scale.
🎓 Developer Mindset: As an engineer, the discipline is knowing when to use Postgres vs Redis vs MongoDB vs Cassandra vs Elasticsearch — not knowing every internal detail of each.
References & Further Reading
https://medium.com/media/d9a857ddc0285dbeeaadd296e07c3941/href🗄️ SQL vs NoSQL: The Simplified System Design Guide was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.



