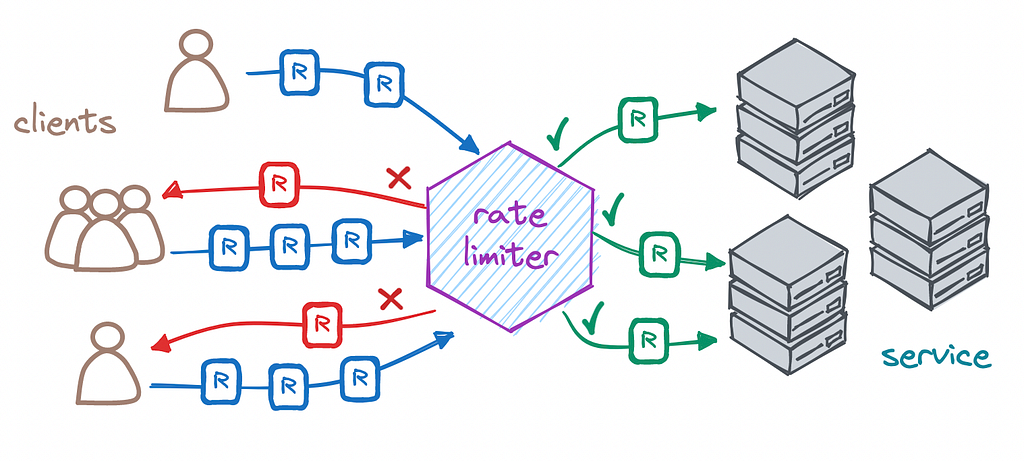
At my day job, I work on systems that handle over 1M daily transactions — API integrations, payment gateways, loyalty platforms. Rate limiting isn’t a theoretical concept for me. It’s something I debug in production on a Tuesday afternoon when a partner API starts rejecting requests because we didn’t handle their throttling correctly.
The Node.js ecosystem already has excellent rate limiting libraries. express-rate-limit and rate-limiter-flexible are battle-tested and widely adopted. I've used them in production. But using a library and understanding what's actually happening when that 429 status code fires back at you are two different things.
So I started building Limitron — a TypeScript-first, framework-agnostic rate limiter with multiple algorithms, Redis-backed distributed state, and atomic Lua scripts for safe concurrent operation. What started as a weekend exploration turned into an open-source library that forced me to confront every edge case I’d been hand-waving away in my head.
This article walks through what I learned — not as a tutorial, but as an honest account of the problems I hit, the design decisions I made, and why distributed rate limiting is harder than most developers think.
The Problem That Started Everything
Here’s the scenario that made me want to build this. We had an Express application running behind a load balancer on three instances. A partner’s API had a rate limit of 100 requests per minute. Simple math: each instance gets ~33 requests per minute and we’re fine, right?
Wrong. Traffic doesn’t distribute evenly. During peak hours, one instance might get 70% of the traffic, blow past the rate limit, and start collecting 429 errors — while the other two instances sat mostly idle. The in-memory rate limiter on each instance had no idea what the others were doing.
The fix was obvious: shared state. Redis. But once you go distributed, you open a different set of problems — race conditions, clock drift, atomic operations, and what happens when Redis itself goes down.
I wanted to understand all of it, from first principles.
Three Algorithms, Three Trade-Offs
Before writing any code, I spent time understanding the fundamental algorithms. Each one makes a different trade-off between accuracy, memory usage, and burst tolerance.
Fixed Window Counter
The simplest approach. Divide time into fixed windows (say, 60-second intervals), increment a counter for each request, and reject once the counter exceeds the limit.
// Conceptual fixed window
const windowKey = Math.floor(Date.now() / windowSize);
const count = await redis.incr(`rate:${userId}:${windowKey}`);
if (count > limit) reject();
The weakness is the boundary problem. If a user sends 100 requests at second 59 of window 1, then 100 more at second 0 of window 2, they’ve made 200 requests in 2 seconds — despite a limit of 100 per minute. This is a well-documented issue, but it’s one of those things you don’t internalize until you see it in your own logs.
Sliding Window Log
This approach stores the timestamp of every single request and counts how many fall within the rolling window. It’s the most accurate — no boundary problems. But it’s also the most memory-intensive. For a high-traffic API, you’re storing potentially thousands of timestamps per user.
// Every request gets logged
await redis.zadd(`rate:${userId}`, timestamp, `${timestamp}-${uuid}`);
await redis.zremrangebyscore(`rate:${userId}`, 0, timestamp - windowSize);
const count = await redis.zcard(`rate:${userId}`);
In my benchmarks, memory usage scaled linearly with traffic — acceptable for moderate loads, but it becomes a concern at scale when you’re rate-limiting millions of unique keys.
Token Bucket
This became my default recommendation. The token bucket algorithm maintains a “bucket” of tokens that refills at a steady rate. Each request consumes a token. When the bucket is empty, requests are rejected.
The elegance is in what it allows: bursts. A user who hasn’t made requests for a while has a full bucket and can send several requests in quick succession. But sustained overuse depletes the bucket and forces them to slow down. This matches how real users actually interact with APIs — they don’t send requests at a perfectly uniform rate.
// Token bucket core logic
const elapsed = now - lastRefill;
const newTokens = elapsed * (maxTokens / windowSize);
const currentTokens = Math.min(maxTokens, storedTokens + newTokens);
if (currentTokens >= 1) {
// Allow request, consume a token
storeTokens(currentTokens - 1);
} else {
// Reject — bucket is empty
reject();
}Why Lua Scripts Aren’t Optional in Distributed Systems
Here’s where things got genuinely difficult. Every algorithm above involves a read-then-write pattern: read the current state, make a decision, write the new state. In a single process, this is trivial. In a distributed system with multiple application servers talking to the same Redis instance, it’s a race condition waiting to happen.
Consider this sequence with two application servers:
Server A: GET counter → 99
Server B: GET counter → 99
Server A: SET counter → 100 (allows request, limit is 100)
Server B: SET counter → 100 (allows request — but this is the 101st!)
Both servers read 99, both decided to allow the request, and now you’ve exceeded your limit. This is the classic check-then-act race condition.
The solution is atomic operations. Redis supports Lua scripts that execute atomically — no other command can interleave during execution. The entire read-decide-write cycle happens as a single unit.
-- Atomic sliding window in Lua
local key = KEYS[1]
local now = tonumber(ARGV[1])
local window = tonumber(ARGV[2])
local limit = tonumber(ARGV[3])
-- Remove expired entries
redis.call('ZREMRANGEBYSCORE', key, 0, now - window)
-- Count current entries
local count = redis.call('ZCARD', key)
if count < limit then
-- Add new entry and allow
redis.call('ZADD', key, now, now .. '-' .. math.random(1000000))
redis.call('EXPIRE', key, math.ceil(window / 1000))
return 1
else
return 0
end
This was the most important lesson in the entire project. Without atomicity, your rate limiter is a suggestion, not a guarantee. Every production rate limiter I’ve seen that has mysterious “off by one” or “off by many” errors traces back to non-atomic state management.
The Redis Failure Problem
Building Limitron forced me to answer a question I’d been avoiding: what happens when Redis goes down?
There are only two options, and neither is great:
Fail closed — reject all requests when Redis is unreachable. Safe, but it means a Redis outage takes down your entire application. Your rate limiter becomes a single point of failure, which is ironic given that it’s supposed to protect your system.
Fail open — allow all requests when Redis is unreachable. Your application stays up, but you have no rate limiting during the outage. An attacker (or a misbehaving client) could hammer your system while it’s already stressed.
I chose fail-open as the default, with configurable behavior. My reasoning: a Redis outage is usually brief (seconds to minutes with proper setup), and during that time, your application’s own capacity limits (connection pools, thread limits, timeouts) provide a rough safety net. Blocking all traffic because your rate limiter’s state store is temporarily unreachable is almost always the worse outcome.
// Fail-open pattern
try {
const result = await redis.eval(luaScript, ...args);
return result === 1 ? allow() : reject();
} catch (error) {
logger.warn('Rate limiter Redis failure, failing open', { error });
return allow(); // Fail open — don't block users for infra issues
}
Making It Framework-Agnostic
Most rate limiting libraries in Node.js are tightly coupled to Express. If you’re using Fastify, Koa, or raw HTTP, you’re either writing adapter code or finding a different library.
I designed Limitron’s core as a pure function with no framework dependencies. The rate limiting logic takes a key and returns a decision — that’s it. Framework-specific middleware is a thin wrapper on top.
// Core — no framework dependency
const limiter = new Limitron({
algorithm: 'token-bucket',
store: new RedisStore(redisClient),
maxRequests: 100,
windowMs: 60000,
});
const result = await limiter.consume('user:123');
// { allowed: boolean, remaining: number, retryAfter: number }// Express middleware — thin wrapper
app.use(limitron.expressMiddleware());
// Fastify plugin — thin wrapper
fastify.register(limitron.fastifyPlugin());
This separation paid off immediately when I needed to rate-limit a background job queue — same algorithm, same Redis state, no HTTP framework involved.
What I’d Do Differently
If I started Limitron again today, three things would change:
1. Start with the sliding window counter, not the log. The sliding window counter (which approximates the rolling window using the previous window’s count) gives 99.997% accuracy according to Cloudflare’s testing — and uses a fraction of the memory. I implemented the full log first because it felt “more correct,” but the counter is the right default for almost every use case.
2. Build observability from day one. I added metrics and logging as an afterthought. In production, you need to know: How often are limits being hit? Which keys are the most throttled? What’s the p99 latency of the rate limiter itself? These questions should shape the architecture, not be bolted on later.
3. Write integration tests against a real Redis instance from the start. Unit tests with mocked Redis gave me false confidence. The first time I ran against an actual Redis cluster with network latency, I found timing bugs that mocks would never catch.
The Broader Lesson
Building Limitron taught me something that applies far beyond rate limiting: the gap between understanding a concept and implementing it correctly in a distributed system is enormous.
I knew what a sliding window was before this project. I could whiteboard a token bucket algorithm in a system design interview. But I didn’t truly understand the race conditions, the failure modes, the operational concerns, or the subtle trade-offs between algorithms until I built one and ran it against real traffic.
The Node.js ecosystem has mature rate limiting libraries, and for most production use cases, you should use them. But if you work with distributed systems — and increasingly, most of us do — spending time building these primitives from scratch, even once, gives you an understanding that no documentation or tutorial can provide.
Limitron is open source. It’s not trying to replace rate-limiter-flexible — it's the artifact of someone who wanted to understand what happens underneath.
I’m a software engineer who builds production systems at scale and writes about what I learn along the way. You can find Limitron on Github and my technical blog at buildwithmayank.hashnode.dev.
If you’re interested in distributed systems, Node.js, or TypeScript — follow me here on Medium for more.
I Built a Distributed Rate Limiter From Scratch in Node.js — Here’s What Production Taught Me was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.


